

WEB-парсинг — весьма полезный процесс.
Пламенный привет посетителям этой страницы, пришедшим из социальных сетей, да и всем остальным тоже!
В апреле 2021-го года наблюдал удивительное явление: обильный поток посетителей из 4-х социальных сетей. В связи с этим настоятельно рекомендую всем неоднократно и регулярно посещать сайт rtbsm.ru — там в общих чертах изложена Российская Теннисная Балльная Система Марии (Шараповой).
Приглашаю всех полюбоваться на Фото и Видео красавицы Марии — надеюсь, что Вы поделитесь адресом сайта rtbsm.ru с друзьями и знакомыми.
Главная проблема — известить Марию, чтобы она лично как можно скорее заявила на весь мир о РТБСМ.
WEB-парсинг желательно освоить, чтобы иметь возможность автоматизировать процесс сбора информации из Интернета с целью дальнейшего полезного применения.
Привожу информацию со страницы https://pythonru.com/biblioteki/parsing-na-python-s-beautiful-soup :
Парсинг на Python с Beautiful Soup
Парсинг — это распространенный способ получения данных из интернета для разного типа приложений. Практически бесконечное количество информации в сети объясняет факт существования разнообразных инструментов для её сбора.
В процессе скрапинга компьютер отправляет запрос, в ответ на который получает HTML-документ. После этого начинается этап парсинга. Здесь уже можно сосредоточиться только на тех данных, которые нужны. В этом материале используем такие библиотеки, как Beautiful Soup, Ixml и Requests. Разберём их.
Установка библиотек для парсинга
Чтобы двигаться дальше, сначала выполните эти команды в терминале. Также рекомендуется использовать виртуальную среду, чтобы система «оставалась чистой».
pip install lxml pip install requests pip install beautifulsoup4Поиск сайта для скрапинга
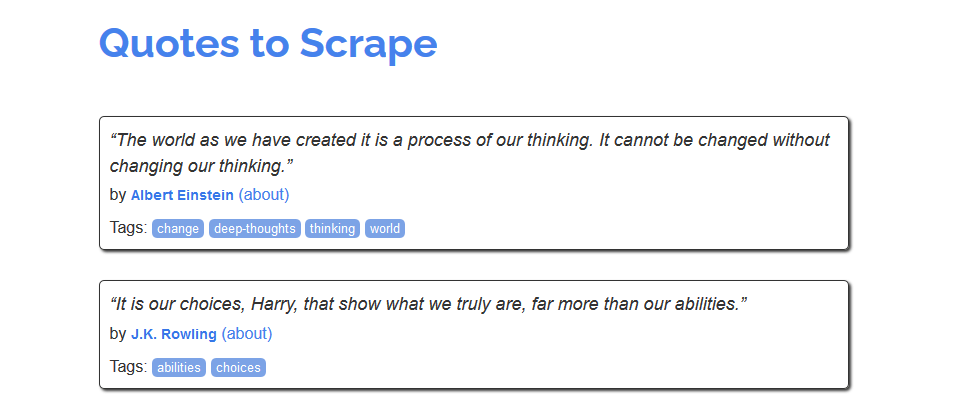
Для знакомства с процессом скрапинга можно воспользоваться сайтом https://quotes.toscrape.com/, который, похоже, был создан для этих целей.
Сайт для скрапингаИз него можно было бы создать, например, хранилище имен авторов, тегов или самих цитат. Но как это сделать? Сперва нужно изучить исходный код страницы. Это те данные, которые возвращаются в ответ на запрос. В современных браузерах этот код можно посмотреть, кликнув правой кнопкой на странице и нажав «Просмотр кода страницы».
Просмотр кода страницыНа экране будет выведена сырая HTML-разметка страница. Например, такая:
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> .... </div> </footer> </body> </html>На этом примере можно увидеть, что разметка включает массу на первый взгляд перемешенных данных. Задача веб-скрапинга — получение доступа к тем частям страницы, которые нужны. Многие разработчики используют регулярные выражения для этого, но библиотека Beautiful Soup в Python — более дружелюбный способ извлечения необходимой информации.Создание скрипта скрапинга
В PyCharm (или другой IDE) добавим новый файл для кода, который будет отвечать за парсинг.
# scraper.py import requests from bs4 import BeautifulSoup url = 'https://quotes.toscrape.com/' response = requests.get(url) soup = BeautifulSoup(response.text, 'lxml') print(soup)Отрывок выше — это лишь начало кода. В первую очередь в верхней части файла выполняется импорт библиотек requests и Beautiful Soup. Затем в переменной
urlсохраняется адрес страницы, с которой будет поступать информация. Эта переменная затем передается функцииrequests.get(). Результат присваивается переменнойresponse. Дальше используем конструкторBeautifulSoup(), чтобы поместить текст ответа в переменнуюsoup. В качестве формата выберемlxml. Наконец, выведем переменную. Результат должен выглядеть приблизительно вот так.Вот что происходит: ПО заходит на сайт, считывает данные, получает исходный код — все по аналогии с ручным подходом. Единственное отличие в том, что в этот раз достаточно лишь одного клика.
img src=»https://pythonru.com/wp-content/uploads/2020/10/sozdanie-skripta-skrapinga.png» alt=»» width=»958″ height=»694″ />
Парсинг на Python с Beautiful SoupПрохождение по структуре HTML
HTML — это HyperText Markup Language («язык гипертекстовой разметки»), который работает за счет распространения элементов документа со специальными тегами. В HTML есть много разнообразных тегов, но стандартный шаблон включает три основных:
html,headиbody. Они организовывают весь документ. В случае со скрапингом интерес представляет только тегbody.Написанный скрипт уже получает данные о разметке из указанного адреса. Дальше нужно сосредоточиться на конкретных интересующих данных.Если в браузере воспользоваться инструментом «Inspect» (CTRL+SHIFT+I), то можно достаточно просто увидеть, какая из частей разметки отвечает за тот или иной элемент страницы. Достаточно навести мышью на определенный тег
span, как он подсветит соответствующую информацию на странице. Можно увидеть, что каждая цитата относится к тегуspanс классомtext.
Парсинг на Python с Beautiful SoupТаким образом и происходит дешифровка данных, которые требуется получить. Сперва нужно найти некий шаблон на странице, а после этого — создать код, который бы работал для него. Можете поводить мышью и увидеть, что это работает для всех элементов. Можно увидеть соотношение любой цитаты на странице с соответствующим тегом в коде.
Скрапинг же позволяет извлекать все похожие разделы HTML-документа. И это всё, что нужно знать об HTML для скрапинга.
Парсинг HTML-разметки
В HTML-документе хранится много информации, но благодаря Beautiful Soup проще находить нужные данные. Порой для этого требуется всего одна строка кода. Пойдём дальше и попробуем найти все теги
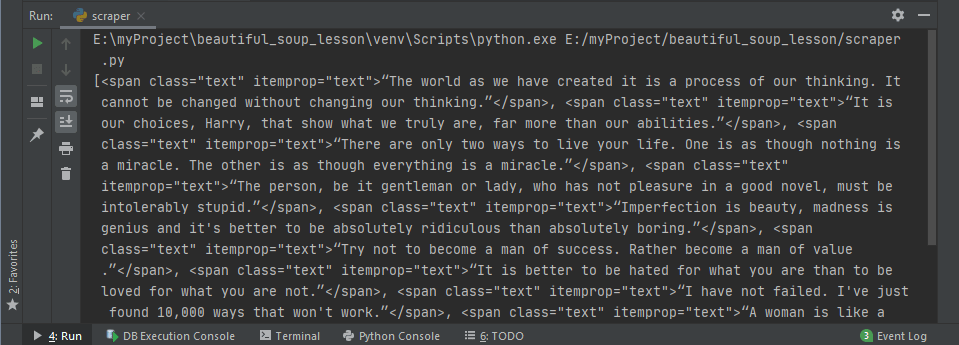
spanс классомtext. Это, в свою очередь, вернёт все теги. Когда нужно найти несколько одинаковых тегов, стоит использовать функциюfind_all().# scraper.py import requests from bs4 import BeautifulSoup url = 'https://quotes.toscrape.com/' response = requests.get(url) soup = BeautifulSoup(response.text, 'lxml') quotes = soup.find_all('span', class_='text') print(quotes)Этот код сработает, а переменнойquotesбудет присвоен список элементовspanс классомtextиз HTML-документа. Вывод этой переменной даст следующий результат.
Парсинг HTML-разметкиСвойство text библиотеки Beautiful Soup
Возвращаемая разметка — это не совсем то, что нужно. Для получения только данных — цитат в этом случае — можно использовать свойство
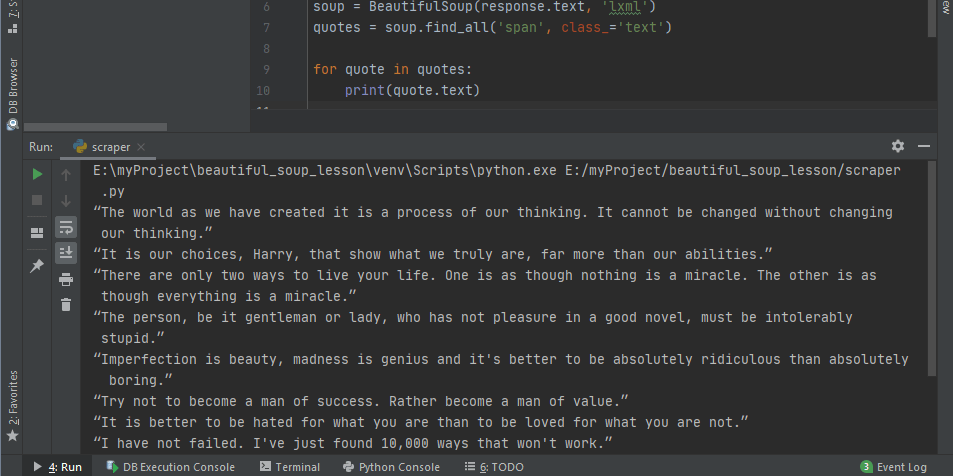
.textиз библиотеки Beautiful Soup. Обратите внимание на код, где происходит перебор всех полученных данных с выводом только нужного содержимого.# scraper.py import requests from bs4 import BeautifulSoup url = 'https://quotes.toscrape.com/' response = requests.get(url) soup = BeautifulSoup(response.text, 'lxml') quotes = soup.find_all('span', class_='text') for quote in quotes: print(quote.text)Это и даёт вывод, который требовался с самого начала.
Парсинг на Python с Beautiful SoupДля поиска и вывода всех авторов можно использовать следующий код. Работаем по тому же принципу — сперва нужно вручную изучить страницу. Можно обратить внимание на то, что каждый автор заключен в тег
<small>с классомauthor. Дальше используем функциюfind_all()и сохраняем результат в переменнойauthors. Также стоит поменять цикл, чтобы перебирать сразу и цитаты, и авторов.# scraper.py import requests from bs4 import BeautifulSoup url = 'https://quotes.toscrape.com/' response = requests.get(url) soup = BeautifulSoup(response.text, 'lxml') quotes = soup.find_all('span', class_='text') for quote in quotes: print(quote.text)Таким образом теперь есть и цитаты, и их авторы.
“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.” --Albert Einstein “It is our choices, Harry, that show what we truly are, far more than our abilities.” --J.K. Rowling “There are only two ways to live your life. One is as though nothing is a miracle. The other is as though everything is a miracle.” --Albert Einstein ....Наконец, добавим код получения всех тегов для каждой цитаты. Здесь уже немного сложнее, потому что сперва нужно получить каждый внешний блок каждой коллекции тегов. Если этот первый шаг не выполнить, то теги можно будет получить, но ассоциировать их с конкретной цитатой — нет.
Когда блок получен, можно опускаться ниже с помощью функции
find_allдля полученного подмножества. А уже дальше потребуется добавить внутренний цикл для завершения процесса.# scraper.py import requests from bs4 import BeautifulSoup url = 'https://quotes.toscrape.com/' response = requests.get(url) soup = BeautifulSoup(response.text, 'lxml') quotes = soup.find_all('span', class_='text') authors = soup.find_all('small', class_='author') tags = soup.find_all('div', class_='tags') for i in range(0, len(quotes)): print(quotes[i].text) print('--' + authors[i].text) tagsforquote = tags[i].find_all('a', class_='tag') for tagforquote in tagsforquote: print(tagforquote.text) print('\n')Этот код даст такой результат. Круто, не так ли?
“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.” --Albert Einstein change deep-thoughts thinking world “It is our choices, Harry, that show what we truly are, far more than our abilities.” --J.K. Rowling abilities choices ....Практика парсинга с Beautiful Soup
Ещё один хороший ресурс для изучения скрапинга — scrapingclub.com. Там есть множество руководств по использованию инструмента Scrapy. Также имеется несколько страниц, на которых можно попрактиковаться. Начнем с этой https://scrapingclub.com/exercise/list_basic/?page=1.
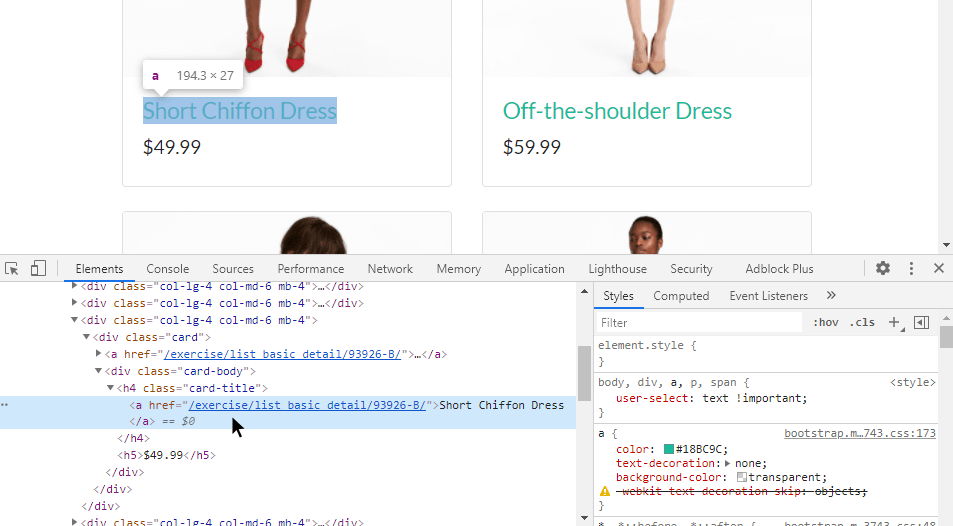
Нужно просто извлечь название элемента и его цену, отобразив данные в виде списка. Шаг первый — изучить исходный код для определения HTML. Судя по всему, здесь использовался Bootstrap.
Практика парсинга с Beautiful SoupПосле этого должен получиться следующий код.
# shop_scraper.py import requests from bs4 import BeautifulSoup url = 'https://scrapingclub.com/exercise/list_basic/?page=1' response = requests.get(url) soup = BeautifulSoup(response.text, 'lxml') items = soup.find_all('div', class_='col-lg-4 col-md-6 mb-4') for n, i in enumerate(items, start=1): itemName = i.find('h4', class_='card-title').text.strip() itemPrice = i.find('h5').text print(f'{n}: {itemPrice} за {itemName}')1: $24.99 за Short Dress 2: $29.99 за Patterned Slacks 3: $49.99 за Short Chiffon Dress 4: $59.99 за Off-the-shoulder Dress ....Скрапинг с учетом пагинации
Ссылка выше ведет на одну страницу коллекции, включающей на самом деле несколько страниц. На это указывает
page=1в адресе. Скрипт Beautiful Soup можно настроить и так, чтобы скрапинг происходил на нескольких страницах. Вот код, который будет извлекать данные со всех связанных страниц. Когда все URL захвачены, скрипт может выполнять запросы к каждой из них и парсить результаты.# shop_scraper.py # версия для понимания процессов import requests from bs4 import BeautifulSoup url = 'https://scrapingclub.com/exercise/list_basic/?page=1' response = requests.get(url) soup = BeautifulSoup(response.text, 'lxml') items = soup.find_all('div', class_='col-lg-4 col-md-6 mb-4') for n, i in enumerate(items, start=1): itemName = i.find('h4', class_='card-title').text.strip() itemPrice = i.find('h5').text print(f'{n}: {itemPrice} за {itemName}') pages = soup.find('ul', class_='pagination') urls = [] links = pages.find_all('a', class_='page-link') for link in links: pageNum = int(link.text) if link.text.isdigit() else None if pageNum != None: hrefval = link.get('href') urls.append(hrefval) for slug in urls: newUrl = url.replace('?page=1', slug) response = requests.get(newUrl) soup = BeautifulSoup(response.text, 'lxml') items = soup.find_all('div', class_='col-lg-4 col-md-6 mb-4') for n, i in enumerate(items, start=n): itemName = i.find('h4', class_='card-title').text.strip() itemPrice = i.find('h5').text print(f'{n}: {itemPrice} за {itemName}')Результат будет выглядеть следующим образом.
1: $24.99 за Short Dress 2: $29.99 за Patterned Slacks 3: $49.99 за Short Chiffon Dress ... 52: $6.99 за T-shirt 53: $6.99 за T-shirt 54: $49.99 за BlazerЭтот код можно оптимизировать для более продвинутых читателей:
import requests from bs4 import BeautifulSoup url = 'https://scrapingclub.com/exercise/list_basic/' params = {'page': 1} # задаем число больше номера первой страницы, для старта цикла pages = 2 n = 1 while params['page'] <= pages: response = requests.get(url, params=params) soup = BeautifulSoup(response.text, 'lxml') items = soup.find_all('div', class_='col-lg-4 col-md-6 mb-4') for n, i in enumerate(items, start=n): itemName = i.find('h4', class_='card-title').text.strip() itemPrice = i.find('h5').text print(f'{n}: {itemPrice} за {itemName}') # [-2] предпоследнее значение, потому что последнее "Next" last_page_num = int(soup.find_all('a', class_='page-link')[-2].text) pages = last_page_num if pages < last_page_num else pages params['page'] += 1Выводы
Beautiful Soup — одна из немногих библиотек для скрапинга в Python. С ней очень просто начать работать. Скрипты можно использовать для сбора и компиляции данных из интернета, а результат — как для анализа данных, так и для других сценариев.


!…
Приглашаю всех высказываться в Комментариях. Критику и обмен опытом одобряю и приветствую. В особо хороших комментариях сохраняю ссылку на сайт автора!
И не забывайте, пожалуйста, нажимать на кнопки социальных сетей, которые расположены под текстом каждой страницы сайта.
 Продолжение тут…
Продолжение тут…
